为什么我推荐你使用 Elasticsearch 实现搜索系统

搜索是一个非常常见的功能,大家肯定都使用过,例如:百度搜索、Google搜索、电商商品搜索、美团商家/食品搜索等等。随着互联网信息爆炸性地飞速增长,网民需要更有效的个性化搜索服务。所以互联网应用几乎没有不开发搜索功能的,既然这个功能这么重要,身为一名合格的程序员必须搞清楚其背后的实现原理。安排!
本文将通过 Spring Boot + Elasticsearch + Vue 实现一个简易版的电商搜索系统,方便大家理解背后的原理。
案例分析
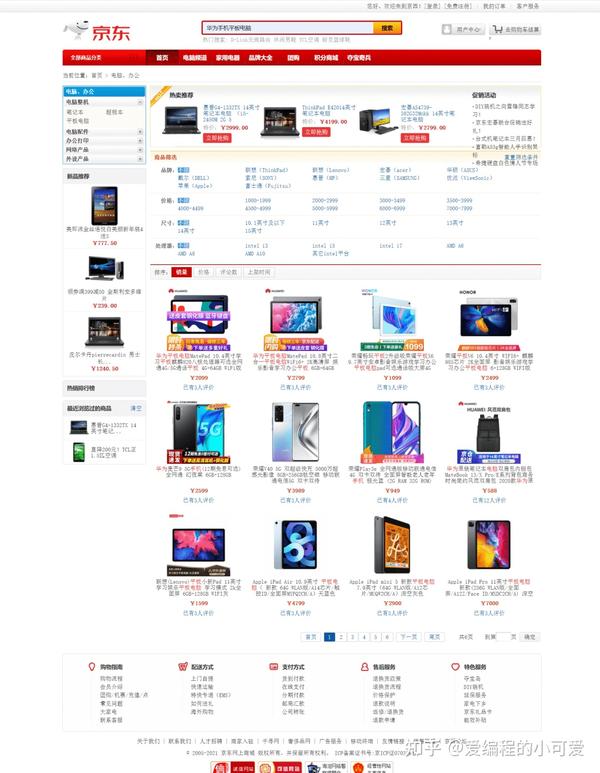

根据上图可以得知,搜索的业务逻辑其实蛮简单的,用户输入要搜索的商品关键词提交以后,将搜索关键词、页码信息等传往后台,后台查询后将结果集进行处理并返回。需要关注的无非以下几点:
- 查询速度要快
- 数据匹配度要高
- 方便排序
- 返回结果高亮
MySQL
核心表(goods)如下:
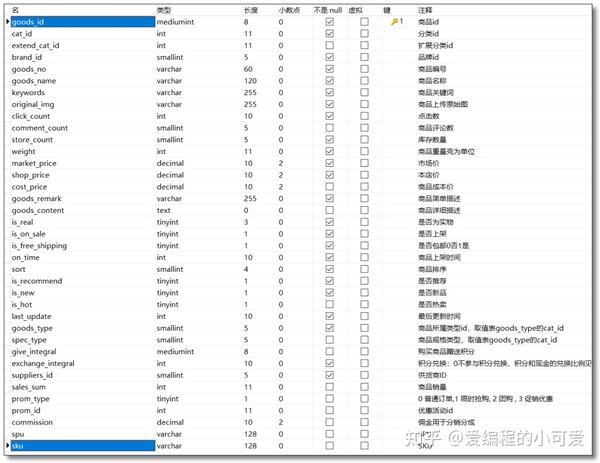

MySQL 商品表的字段是非常多的,而商城搜索页面所需要的数据无非就是商品ID、商品名称、商品价格、商品评论数和商品原始图等(根据自己实际开发情况而定,这里根据本文案例前端样式进行分析)。一般商品表还会添加商品关键词字段专门方便搜索引擎使用,所以一条单表 SQL 查询相信应该难不倒各位。
我们先不考虑数据库性能方面的问题,就单纯为了实现这个功能来看看都需要做什么:
- 假设搜索条件是
华为手机平板电脑,要求是只要满足了其中任意一个词语组合的数据都要查询出来,SQL 怎么写?换句话说你打算写多少条 SQL? - 假设上一步你做完了,拿到那么多的结果集你是不是要考虑去重排序一下?
- 前两步你都实现了,现在我的要求是返回前端时必须将刚才搜索条件中的词语组合进行高亮处理
WTF ,接到这样的需求如果让你用关系型数据库去实现,的确有点强人所难。怎么办?往下看。
Elasticsearch
随着互联网信息爆炸性地飞速增长,传统的查询方法已无法为网民提供有效的搜索服务。如果我们做的只是用户量很少的内网项目,并且搜索的字段都是一些内容很简短的字段,比如姓名,编号之类的,那完全可以用数据库 like 语句,但是,数据库 like 查询性能非常低,如果搜索的请求过多,或者需要搜索的是大文本类型的内容(全文搜索),那么这种搜索的方案也是不可取的。
互联网的飞速发展迫切地需求一种快速、全面、准确且稳定可靠的信息查询方法。既然我们要做性能高的全文搜索,这个需求又不能依赖数据库,只能由我们自己来实现了。但是令我们很受打击的是全文搜索是很难实现的,我们不仅希望能全文搜索,还希望它足够稳定足够快,且搜索结果有关键字高亮,还能按各种匹配分数来排序,希望它能切换不同的分词算法来满足各种分词需求。
综上所述,如果我们想要做一个功能完善,性能强大的全文搜索其实并非易事,而全文搜索又是一个常见的需求,在这种环境下,市面上出现了一些开源的解决方案。这些解决方案开源出来后,获得了大量的社区开发者支持,不断为其开发插件,使其不断优化和完善,这就成了我们所说的搜索引擎了。而它们中最有名气的就是 Elasticsearch 和 Solr。
Elasticsearch 是一个基于 Apache Lucene 的搜索服务器。它提供了一个分布式多用户能力的全文搜索引擎,基于 RESTful web 接口。Elasticsearch 是用 Java 开发的,并作为 Apache 许可条款下的开放源码发布,是当前流行的企业级搜索引擎。设计用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用方便。Elasticsearch 是最受欢迎的企业搜索引擎,其次是 Apache Solr,也是基于 Lucene。
如果使用 Elasticsearch 来做这件事,刚才的问题都会迎刃而解:
- Elasticsearch 易于安装和配置,学习和使用成本较低,开箱即用。
- Elasticsearch 支持单机也支持分布式,内置分布式协调管理功能,天生集群。
- Elasticsearch 提供了分片和副本机制,一个索引可以分成多个分片,一个分片可以设置多个复制分片,提高效率和高可用。
- Elasticsearch 注重于核心功能实现,高级功能多有第三方插件提供,例如图形化界面 Kibana 的支撑。
- Elasticsearch 建立索引快,实时性查询快,适用于新兴的实时搜索应用,面对海量数据也毫不逊色,速度快,负载强。
- Elasticseach 有强大的文本分析功能(分词)和倒排索引机制,进一步提升搜索速度。
分词
刚才我们提到的问题中,假设搜索条件是华为手机平板电脑,要求是只要满足了其中任意一个词语组合的数据都要查询出来。借助 Elasticseach 的文本分析功能可以轻松将搜索条件进行分词处理,再结合倒排索引实现快速检索。Elasticseach 提供了三种分词方法:单字分词,二分法分词,词库分词。
单字分词:
如:“华为手机平板电脑”
效果:“华”、“为”、“手”、“机”、“平”、“板”、“电”、“脑”
二分法分词:
按两个字进行切分。
如:“华为手机平板电脑”
效果:“华为”、“为手”、“手机”、“机平”、“平板”、“板电”、“电脑”。
词库分词:
按某种算法构造词,然后去匹配已建好的词库集合,如果匹配到就切分出来成为词语。通常词库分词被认为是最理想的中文分词算法。而词库分词最常用的就是 IK 分词。
IK 分词器提供两种分词模式:
ik_max_word:会将文本做最细粒度的拆分,比如会将“中华人民共和国国歌”拆分为“中华人民共和国,中华人民,中华,华人,人民共和国,人民,人,民,共和国,共和,和,国国,国歌”,会穷尽各种可能的组合,适合 Term Query。ik_smart:会将文本做最粗粒度的拆分,比如会将“中华人民共和国国歌”拆分为“中华人民共和国,国歌”,适合 Phrase Query。
倒排索引
对于搜索引擎来讲:
- 正排索引是文档 ID 到文档内容、单词的关联关系。也就是说通过 ID 获取文档的内容。
- 倒排索引是单词到文档 ID 的关联关系。也就是说通过单词搜索到文档 ID。
倒排索引的查询流程是:首先根据关键字搜索到对应的文档 ID,然后根据正排索引查询文档 ID 的完整内容,最后返回给用户想要的结果。
组成部分
倒排索引是搜索引擎的核心,主要包含两个部分:
- 单词词典(Trem Dictionary):记录所有的文档分词后的结果。一般采用 B+Tree 的方式,来保证高效。
- 倒排列表(Posting List):记录单词对应的文档的集合,由倒排索引项(Posting)组成。


倒排索引项(Posting)主要包含如下的信息:
- 文档 ID,用于获取原始文档的信息。
- 单词频率(TF,Term Frequency),记录该单词在该文档中出现的次数,用于后续相关性算分。
- 位置(Position),记录单词在文档中的分词位置(多个),用于做词语搜索。
- 偏移(Offset),记录单词在文档的开始和结束位置,用于高亮显示。
案例
倒排索引参考文献《这就是搜索引擎:核心技术详解》张俊林著。
假设文档集合包含五个文档,每个文档内容如下图所示。在图中最左端一栏是每个文档对应的文档编号。我们的任务就是对这个文档集合建立倒排索引。
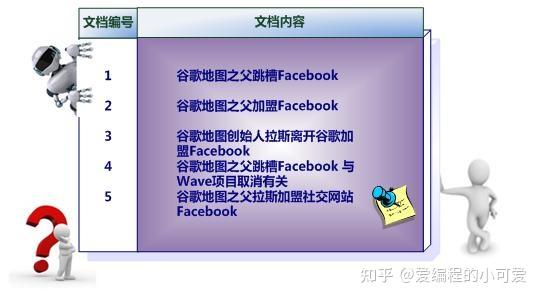

首先用分词系统将文档自动切分成单词序列。为了系统后续处理方便,需要对每个不同的单词赋予唯一的单词编号,同时记录哪些文档中包含这个单词,在如此处理结束后,我们可以得到最简单的倒排索引,如下图所示。
在图中,“单词 ID”一栏记录了每个单词的单词编号,第二栏是对应的单词,第三栏即每个单词对应的倒排列表。比如单词 谷歌,其单词编号为 1,倒排列表为 1,2,3,4,5,说明文档集合中每个文档都包含了这个单词。
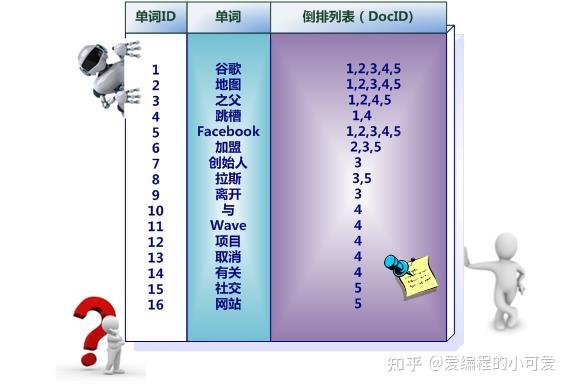

为了方便大家理解,上图只是一个简单的倒排索引,只记录了哪些文档包含哪些单词。而事实上,索引系统还可以记录除此之外的更多信息。
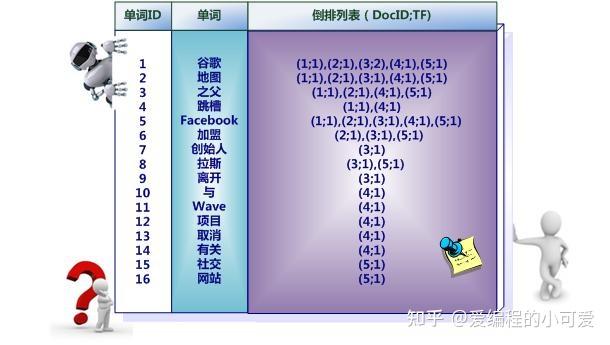
下图则是一个相对复杂的倒排索引,在单词对应的倒排列表中不仅记录了文档编号,还记录了单词频率信息(TF),即这个单词在某个文档中出现的次数,之所以要记录这个信息,是因为词频信息在搜索结果排序时,计算查询和文档相似度是很重要的一个计算因子,所以将其记录在倒排列表中,以方便后续排序时进行分值计算。
图中单词 创始人 的单词编号为 7,对应的倒排列表内容为 (3;1),其中 3 代表文档编号为 3 的文档包含这个单词,数字 1 代表词频信息,即这个单词在 3 号文档中只出现过 1 次。

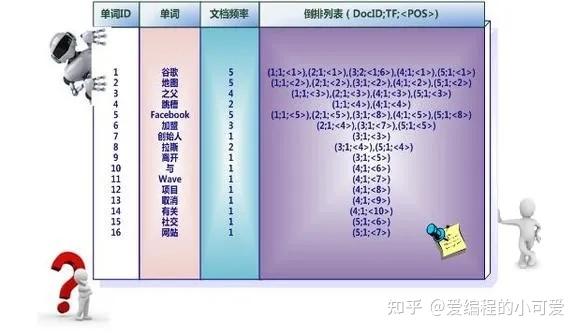
实用的倒排索引还可以记录更多的信息,如下图所示索引系统除了记录文档编号和单词频率信息外,额外记载了两类信息,即每个单词对应的“文档频率信息”以及在倒排列表中记录单词在某个文档出现的位置信息(POS)。

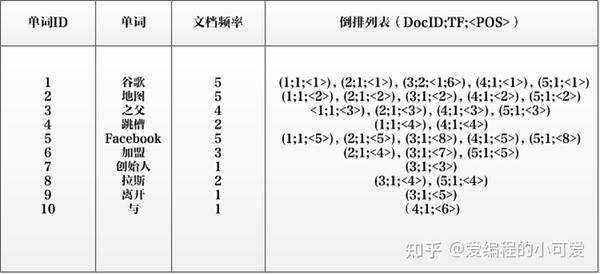

有了这个索引系统,搜索引擎可以很方便地响应用户的查询,比如用户输入查询词“Facebook”,搜索系统查找倒排索引,从中读取包含这个单词的文档,这些文档就是提供给用户的搜索结果。
利用单词频率信息、文档频率信息可以对这些候选搜索结果进行排序,计算文档和查询的相似性,按照相似性的得分由高到低排序输出。
感谢大家关注:《乐字节教育》,下期将带大家进入实战环节