
多维空间中的高效索引算法

我们每天使用的百度地图、美团等等导航、搜索附近的餐厅、美食、POI、共享单车等APP被统称为基于位置的服务,LBS,这些都是依赖于强大的地图数据库。
我们每次点开地图的时候,比如打开滴滴app的时候,附近的车辆能够很快的呈现出来。很常见,但是很不普通。
假设地图上会显示以自己为圆心1000米以内的车辆,如何实现呢?最直观的想法就是去数据库里面查表,计算并查询车距离用户小于等于5公里的,筛选出来,把数据返回给客户端。这种做法比较笨,一般也不会这么做。为什么呢?因为这种做法需要对整个表里面的每一项都计算一次相对距离。这样的穷举算法,是非常耗时的。因为这是以你为中心,对整个表内的点计算一遍距离,试想如果表格存储的是整个地球表面的所有的点,点的精度是0.0001度,1度大约111公里。
自然而然的,我们会想到把地图分块。这样即使每一块里面的每条数据都计算一次相对距离,也比之前全表都计算一次要快很多。如果你是刚学地图学,还没接触数据结构、数据库,那么剩下的内容可能有点难度。
更进一步,为离散的点建立拓扑关系。大家都知道栅格图像数据具有规则的格网加持,它是自带拓扑关系的,可以随意的查询最近邻的栅格,但是空间中的离散的点没有。像arcgis这一类的地理信息软件能够支持高效的空间分析、查询,是因为其数据库管理系统 (DBMS)具备空间索引功能。空间索引的建立通常依赖于树形数据结构,如KD树、八叉树,搜索相邻的Node就可以找到近邻的Point。
以三维空间中八叉树为例,一个空间内的盒子要用2^3个子节点划分,当点的数量很大,八叉树建立、遍历和维护的难度大。
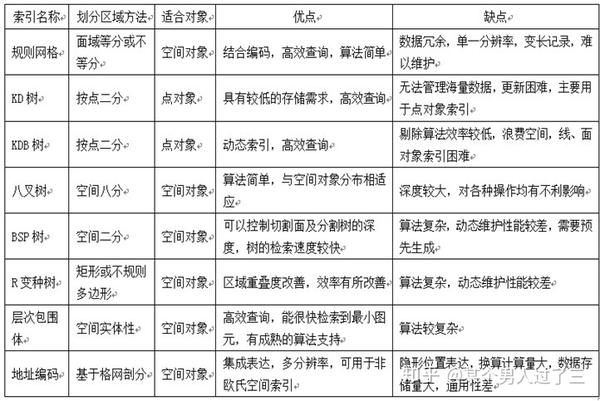

树形的空间索引,不是最优的解决办法。
更好的办法:
把高维空间映射到一维空间。每一个高维空间中的点都有一个身份证,用二分法。

这个方法,我曾经用到过 图像分割、区域合并中,把提取的区域特征、映射、压缩,可以更快的进行比较分析。


如今这一类方法已经用到了LBS大厂商的地图产品中。。。
我也得到一些新的启发。
未完待续。